Epistemic Status:  Sprouting — This is a very nascent idea that I’ve been tossing around. Definitely a lot more unanswered questions than answers.
Sprouting — This is a very nascent idea that I’ve been tossing around. Definitely a lot more unanswered questions than answers.
Recently I read a blog post about the real cost of an interruption and context switching that touched on some things I’ve been thinking about around how to better organize how software work is done. There’s space here for new ways of looking at editing code that I think might be worth exploring.
I’ll start with a question that has been driving this thought process. Can we navigate and organize code better if we aren’t stuck thinking of source code as text files? *Don’t get me wrong, text files are great for their interoperability. With the widespread use of code formatters, we clearly don’t want to care about how the bytes are laid out in the source files that much.
Before I start...
I just want to say from the outset, I’m not talking about visual programming here. While those systems have good intentions, I think it would be foolish to completely move away from source code as text. Language is one of our most useful tools, and we should continue to use that where it makes sense to do so.
Some of the ideas here are inspired by Smalltalk and Unison, two languages whose approach to source code management are well off the beaten path. That’s as good a place to start as any.
How Smalltalk manages source code
Smalltalk is an image-based language, which means that the entire system is kinda like an operating system. It contains the GUI system, the compiler, the debugger, the editor, and so forth. I haven’t done any large scale programming with Smalltalk so I can only talk about it in the broad strokes.
The main way you edit code is through the System Browser. This is a screenshot of the System Browser from Squeak, a modern implementation of Smalltalk1.
This is the CompiledCode initialize class method. I don’t know what it actually does in the wider context of the compiler.
Smalltalk is from a different time. Those "strings of text" are actually comments.
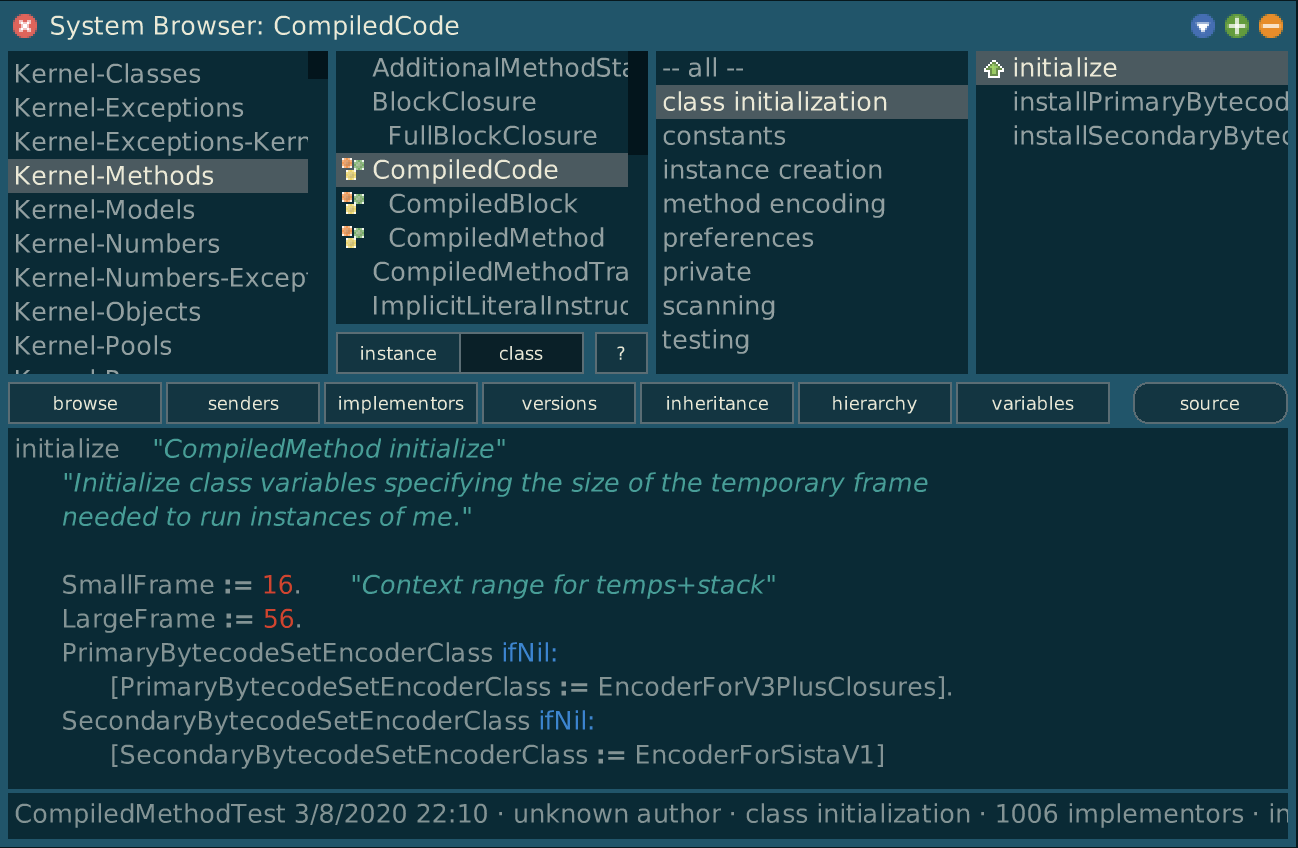
The top four panes are for navigation. The first pane lists packages, the second classes, the third categories or groupings of methods, and finally in the last pane, methods2 themselves.
The bottom pane is the source editor. To edit code, you use the top panes to navigate to them, *There are more direct ways to navigate to particular methods, but that’s beyond the scope of this discussion. and that changes the contents of the source editor. There you make edits, and when you’re done, you can save those changes, and have them immediately applied to all instances of that class that are currently live in the system.
That live editing is very powerful and unlocks new ways to write and debug software. For example, when writing new code, you can leave methods undefined, and when that code is executed, the environment will give you the option to then define it, and then continue running as though it was always there. There are no separate edit-compile-run steps, because they’re all combined into one tight loop. You edit code and save it, that compiles the code, and your program, i.e. the whole system, is already running so it takes effect immediately.
In this way, Smalltalk has text source code, but it doesn’t have source text files. There are ways to write out the source to text files if you really want to, but that’s not the usual way it’s used.3
How Unison manages source code
Unison does things a little differently. The main way you interact with the system is via the Unison Codebase Manager, or UCM, which is also the name of the program, ucm. *Unison is very new, so this could all completely change at some point.
Here is an example of using it. Currently, you run the ucm in a terminal window, and then edit a file, usually scratch.u that the UCM watches and interacts with. You can see on the right, each time I save the file, the UCM looks for and typechecks any definitions it finds. It also runs any “watch expressions” and unit tests that are defined.
The Unison website has a full tutorial if you’re interested.
Syntactically, Unison is very similar to Haskell. It’s a functional statically typed language.
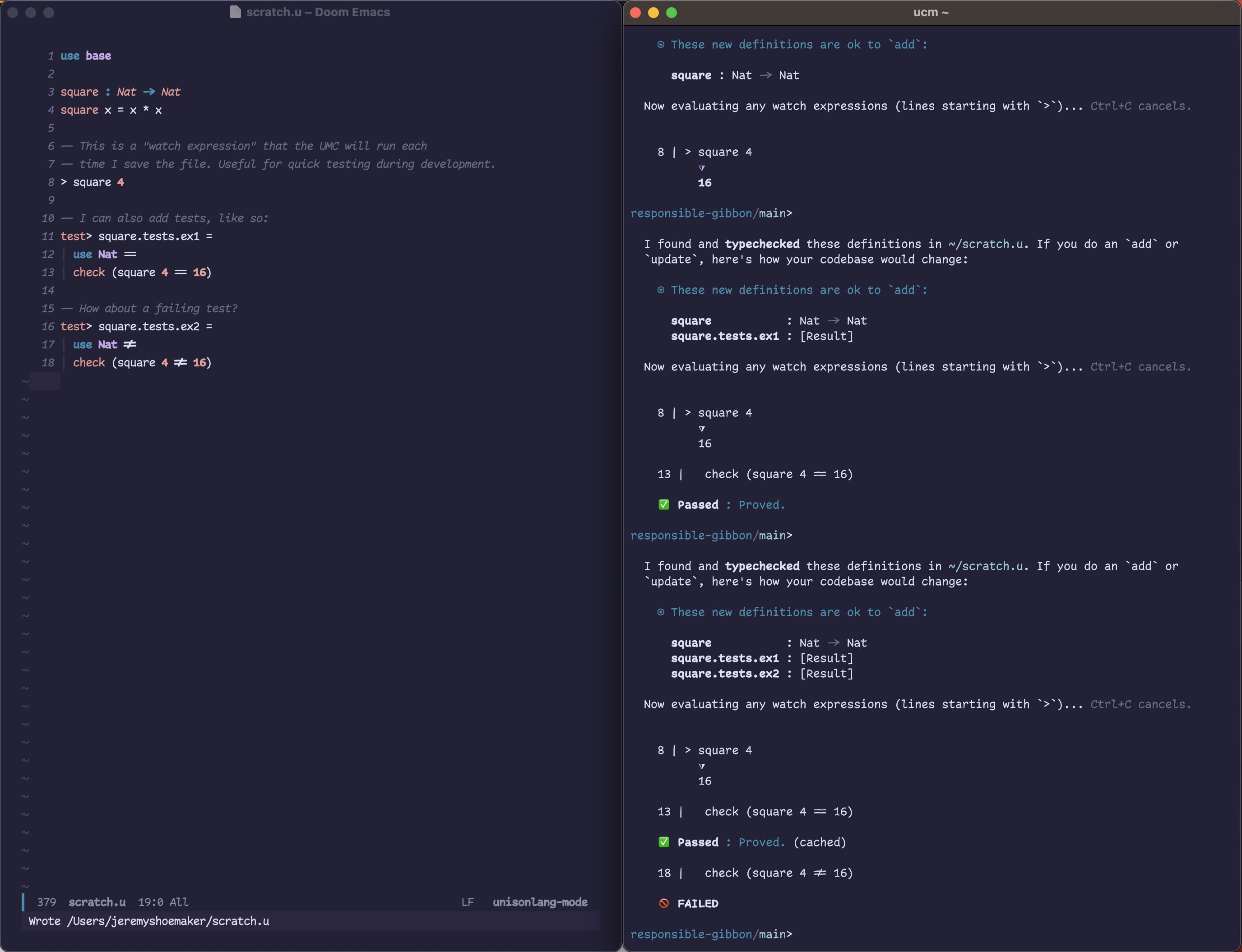
The important point here is that the text file I’m editing here, scratch.u, is NOT a source text file in the traditional sense. I wouldn’t check it into Git or anything like that. The code isn’t “saved” until I tell the UCM to add it (as the messages in the terminal window indicate).
When I want to come back and “edit” an existing definition, I ask the UCM to edit it, and it updates scratch.u with the text of the definition. The contents of scratch.u are ephemeral.
Why would you go through all this trouble?
The part I haven’t told you is that Unison’s code definitions are stored in a database and those definitions are content addressed using a hash of their syntax tree. *This is Unison’s self-described “big idea”. The text I wrote is just a representation of the code. This opens up all kinds of new possibilities that we haven’t been able to consider before because we’ve been stuck thinking about source text files.
That’s cool, but how does this apply to work
Going back to the blog post I mentioned at the top of this page, I’ve been thinking of ways to manifest my mental context while working on a codebase into something that I can see and interact with, and most importantly save and come back to later. Being able to “connect the dots” and even keep notes would be invaluable.
Unison and Smalltalk are great, but if you’re writing some other language, like Python or Elixir, then you’re stuck with what those languages are built around, which is source code text files.
Some existing tools can sometimes obscure the fact that everything is a text file. An example of this is how I usually use something like a Jetbrains IDE to edit code. These tools are so feature filled that I often don’t need to know what file a function or class is in. When your tools can write your import statements for you, or take you to class or symbol definitions directly by name from anywhere, or show usage sites, then navigating a file structure becomes less important.4
Building blocks for a solution
Several tools have arrived in recent years that could help with this idea. One of them is Tree-sitter and the other is Language Server Protocol or LSP. I’ll briefly summarize what each brings to the table.
Tree-sitter
Tree-sitter is a parser library for building concrete syntax trees with a focus on code editing applications. Obviously this can be used for it’s intended purpose of syntax highlighting but I think this could also be used for indexing a codebase as well to drive search based off of syntax types, e.g. by class or symbol.
Language Server Protocol
This is a protocol for language servers that can provide editor-agnostic IDE-like features. The idea being that instead of each editor having to implement the same features over and over, they can just implement this protocol and then each language has one or two LSP servers that do all the heavy lifting.
If I’m being honest, I’ve found these to be disappointingly lacking compared to tools like IntelliJ or PyCharm. *I’ve often wondered if the missing features are because the implementers don’t know what they’re missing. I’m always open to it improving, so I check in from time to time.
A sketch of an idea
So, finally I can talk about my idea. Recently I noticed Obsidian added a feature called Canvas that almost provides the interface that I’ve been imagining I’d want in this new style of code editor and might even be a starting point for a prototype.
This is a screenshot of a Canvas I made recently while working on a ticket at work, adding caching of TypeScript results in CircleCI.5
Nothing special here. Just working on changes to CircleCI.
It would be nice if CircleCI’s website had a dark mode.
I also can’t link directly to this header on the CircleCI page which is annoying.

This is a visual representation of all the information that I need to make the changes I’m making. For a more complex task, this would be more involved, but it would be something I could look at, show to others, and set down and pick up easily.
In the left two panes, you can see two webpages open in cards.
The first is the Jira ticket I’m working on and the second is the CircleCI documentation (a blog actually) relevant to what I’m working on. Notice that they’re both showing only the parts I need right now. Imagine if this were to allow me to pull out specific elements from the HTML content to show, just the ones I need for this work and nothing else. I also connected the first one to the second with an arrow mentioning that the CircleCI page is the one referenced in the ticket.
The middle card is a simple Markdown card showing notes on what I need to do, and a diff of the changes I’ve already made to the TypeScript config. Imagine if that was driven from an actual diff?
Then at the top is a short checklist of tasks to complete for this.
The bottom and far right cards are both opened to the source code at relevant lines. For this Canvas, they’re just GitHub source pages with the relevant lines selected but imagine they were actual code editors scoped to just the structural part of the file I’m interested in (using Tree-sitter’s AST to find the start and end).
I only ever care about the single function or maybe even a whole class that I’m working on, not really what file they’re in. But I’d like to be able to juxtapose functions from completely different parts of the system, to follow the call graph, and see them all together. *A lot of Canvas is mouse driven, though there are shortcuts, and there’s nothing that would prevent coming up with a completely keyboard driven approach.
Imagine these individual editor cards having controls to step up and down the syntax tree expanding or narrowing the focus as needed and storing that information in a way that can easily be reloaded in the future.
Recall from earlier that the Smalltalk System Browser only allowed for focusing on a single method at a time6.
This Canvas is also infinitely scrollable and zoomable, *Canvas has grouping functionality that I’m not showing here but would be useful if I’m working on multiple separate tasks. so in a view like this I can keep notes related to the parts of the task I’m working on unconstrained by the size of my screen. A Canvas can even include another Canvas if that structure would work better.
If I want to focus on an editor card, I can zoom until it fills the screen, or I can zoom back a little to see the related parts of the task I’m working on, or all the way out to a bird’s eye view.
Remembering what I said earlier about using Tree-sitter to index the codebase, I’d prefer to lean towards having the system track files for me and not worry about them directly, navigating only by symbol search and other options.
This sort of system, used as I’ve described here would certainly help me keep track of what I’m working on better and in a way that could easily be stopped at the end of the day and picked up the next, or for random interruptions, without a total loss of context.
Aren’t you just describing a window system?
This does seem to have some overlap with an overlapping window manager, but there are a few things to note here.
In this “sketch”, Obsidian Canvas is keeping track of where all these cards are and saving them in a .canvas file, which is just a small JSON file. It’s also providing the Markdown editing for the regular cards (which can also be backed by separate pages).
The Canvas also doesn’t really lend itself well to overlapping cards. You wouldn’t want to, or need to, when you have an infinite surface to work on.
I also haven’t even begun to consider ways in which the cards could interact with each other, something more difficult to do with separate programs in a windowing system. *All this talk of cards and I can’t help but think of HyperCard and how it might influence this as well.
Going further
I could see coming up with a system for storing arbitrary language content in a way similar to what Unison does, content addressed with all the features that unlocks, and only actualizing them into source text files when needed for the underlying language.
That’s further off and probably needs to be proved out in Unison first.
Another direction this could go is as a format for conveying change information to others. I’ve thought a lot about how we do code review, and how much of the process is influenced by our file-based approach. I’ve pitched the idea of what I’ve called literate code review after Knuth’s idea of presenting code in an order suitable for understanding and not necessarily the order demanded by the machine, but I haven’t put it into practice.
I’m excited about this and plan to keep using Obsidian Canvas to sort of “pretend” use it as a prototype until I have time to actually implement something. *Obsidian does support plugins, so maybe I could add the functionality I want?
Footnotes
-
Smalltalks today trace their lineage back to Smalltalk-80, which is described in the book Smalltalk-80: The Language and its Implementation, also known as the “Blue book” for its blue cover image. This book thoroughly describes the language, its standard library, and has instructions for how to implement a Smalltalk system. It’s worth a read.

-
Smalltalk is one of the original object oriented languages, though Alan Kay has said he probably should have focused on the message passing instead, since later object oriented languages missed the point.
-
You might ask, how do you do source control? That functionality is built into the system and for some Smalltalks, this can interact with traditional source control systems like Git.
-
I haven’t mentioned Jupyter or Livebook style notebooks. Those serve a different purpose and don’t really get away from the file-based approach. But they do have some positive features. There might be some features of Jupyter that are heading in this direction, I haven’t used it recently to know. is another project with similarities to the ideas discussed here but it’s focused on Clojure.
-
You might wonder, for such a simple task why go through the trouble of making this? Well first of all, I haven’t used CircleCI so I need to learn that nor have I worked with the TypeScript compiler very much. It also makes a perfect simple example for this.
-
You can, of course, open multiple System Browser windows in Smalltalk, but it’s stuck with the fixed space desktop metaphor, not the infinite space of something like this.